Ollama auf einem VPS mit 1Panel: privates KI-Labor in 10 Minuten
Schritt-für-Schritt: Ollama auf einem VPS mit 1Panel. Private LLMs ohne API-Keys — in unter 10 Minuten einsatzbereit.
Kurzfassung
Ollama führt Open-Source-LLMs (Llama 3, Mistral, DeepSeek-R1) auf Ihrem VPS aus — ohne API-Keys, ohne Tokenkosten, Daten verlassen den Server nicht. Mit 1Panel dauert die Installation aus dem App Store etwa 2 Minuten; inklusive erstem Modell oft unter 10 Minuten. Minimum: 4 vCPU, 8 GB RAM, Ubuntu 22.04+.
Einleitung
Cloud-KI-APIs sind bequem, aber teuer und schwer kalkulierbar. Ollama vereinfacht lokale LLMs: Download, Laufzeit, API — in einem Tool. 1Panel ergänzt einfache Installation, Monitoring und Sicherheit per Klick.
Diese Anleitung: Anforderungen, Installation, Modellwahl, Härtung, Kostenvergleich.
Was ist Ollama?
Open-Source-Laufzeit für große Sprachmodelle: Modell ziehen, lokal betreiben, OpenAI-kompatible REST-API.
Merkmale:
- Modellverwaltung (Download, Versionen, Löschen)
- Lokaler API-Server auf Port
11434 - CPU/GPU-Erkennung und Quantisierung
- 100+ gängige Modelle
Mindestanforderungen VPS
Ollama läuft auch CPU-only; GPU ist optional.
| Einsatz | CPU | RAM | Speicher | Geschwindigkeit (ca.) |
|---|---|---|---|---|
| Leicht (7B) | 4 vCPU | 8 GB | 20 GB SSD | 5–15 Tokens/s |
| Standard (13B) | 8 vCPU | 16 GB | 40 GB SSD | 3–8 Tokens/s |
| Schwer (70B) | 16 vCPU | 64 GB | 100 GB SSD | 0,5–2 Tokens/s |
Empfehlung zum Start: 4 vCPU / 8 GB RAM / Ubuntu 22.04 LTS.
Braucht Ollama eine GPU?
Nein. CPU reicht für viele Einzelpersonen und kleine Teams. GPU verbessert Durchsatz und Latenz bei größeren Produktionslasten.
Installation mit 1Panel
Schritt 1: 1Panel installieren
bash -c "$(curl -sSL https://resource.1panel.pro/v2/quick_start.sh)"
Schritt 2: App Store
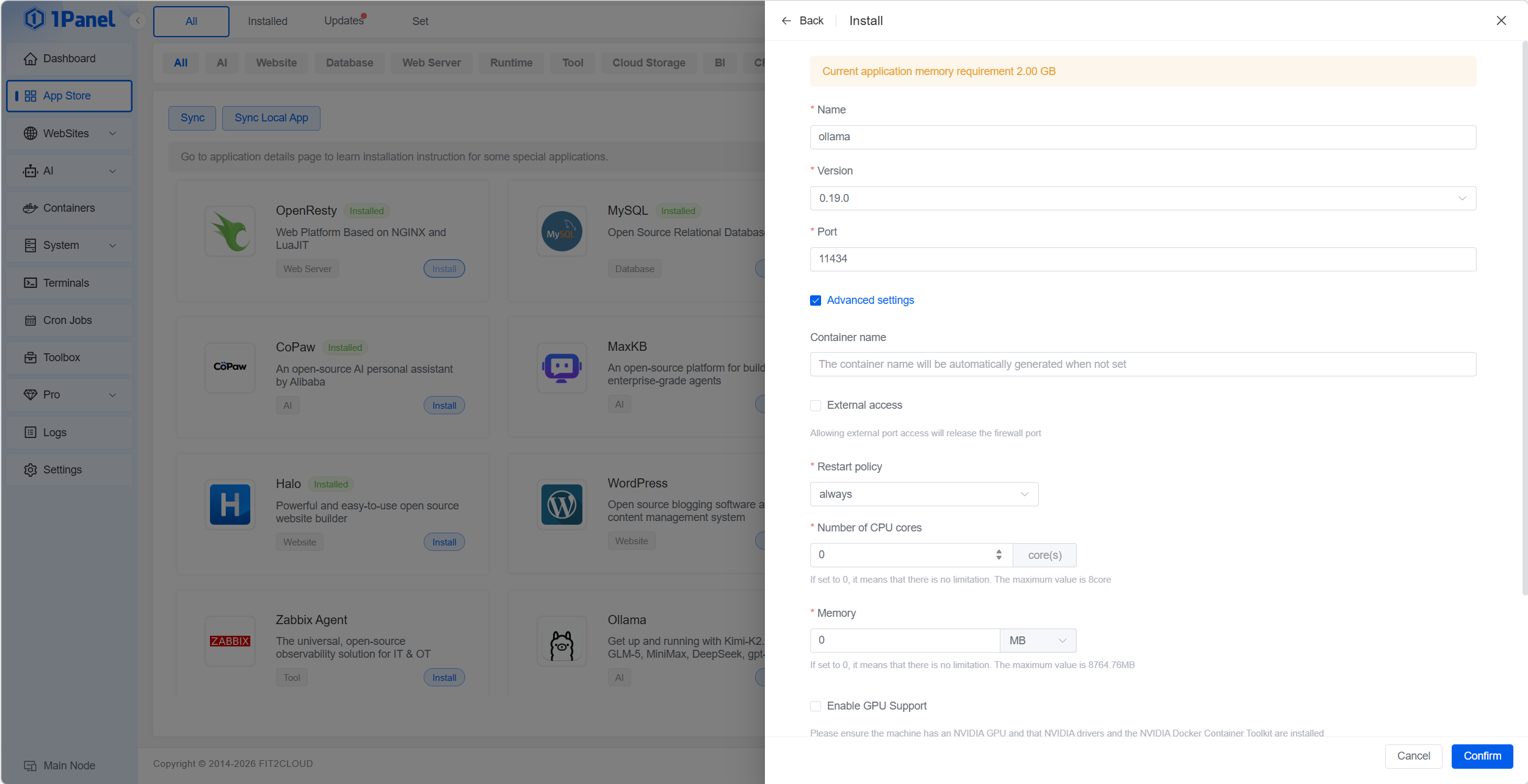
In der Seitenleiste App Store → Ollama suchen → Installieren.
Schritt 3: Optionen
- Port Standard
11434 - Optional CPU/RAM-Limits
- Datenverzeichnis für Modelle
- Externer Zugriff, wenn Ollama von außen erreichbar sein soll
Schritt 4: Erstes Modell
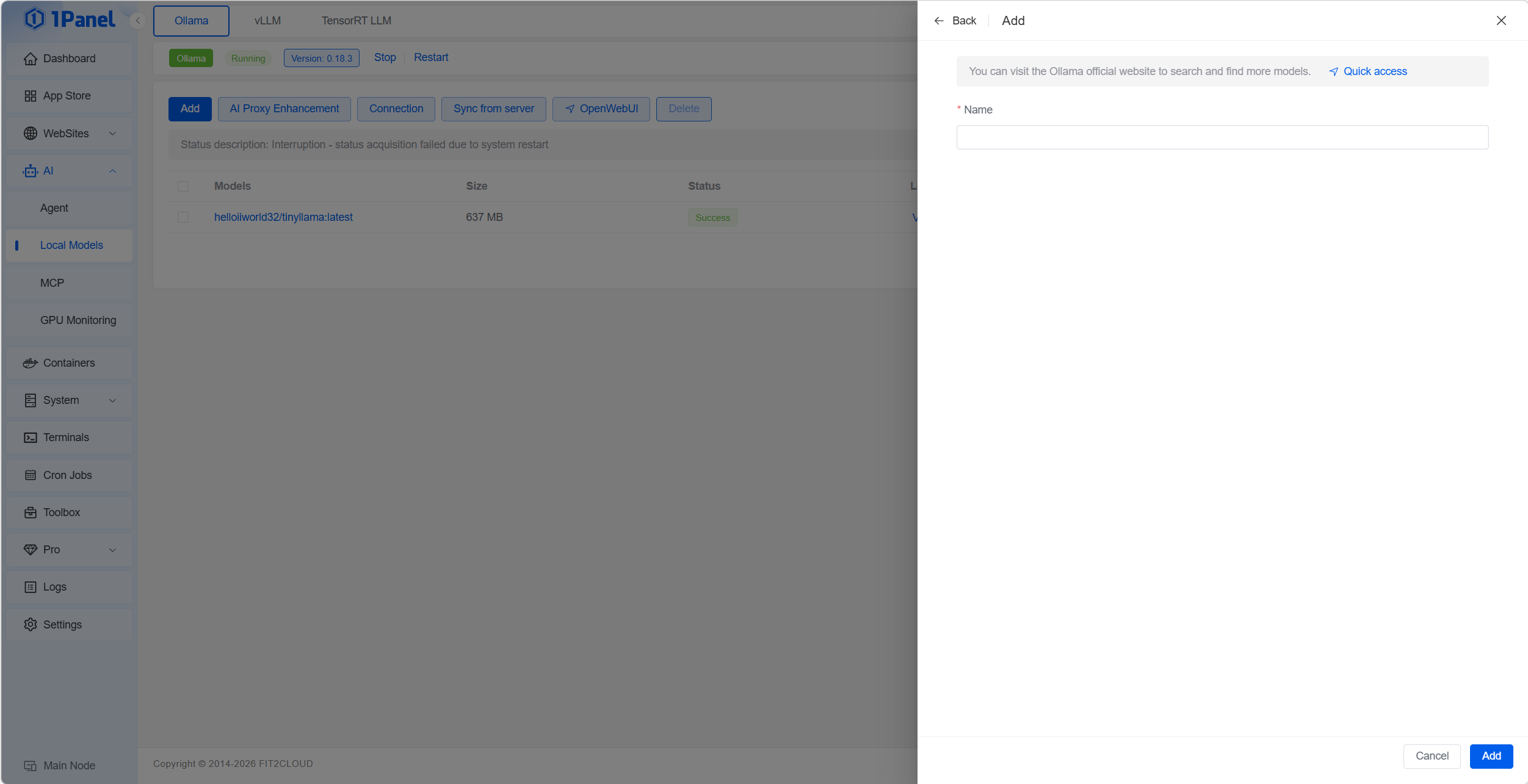
KI → Lokale Modelle → Ollama → Hinzufügen — Modellname eintragen; Ollama lädt und startet automatisch. Übersicht: ollama.com/search.
Schritt 5: Chat testen
Nach Download Ausführen neben dem Modell — oder per API:
curl http://{SERVER_IP}:11434/api/generate -d '{
"model": "llama3",
"prompt": "Erkläre Self-Hosted-LLMs in einem Satz.",
"stream": false
}'
Schritt 6: Absicherung
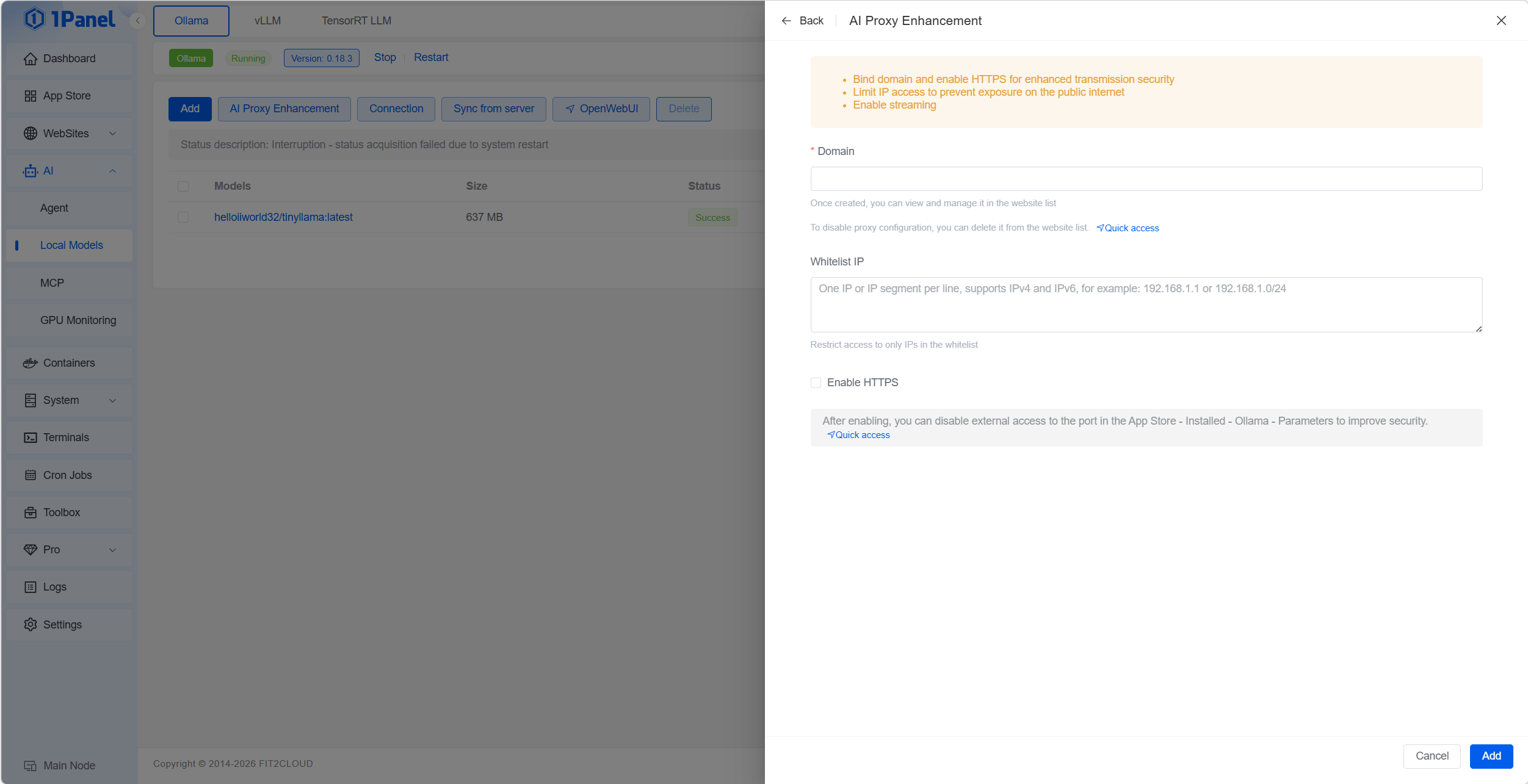
Für Endnutzer: KI-Proxy-Verbesserung — Reverse Proxy und HTTPS.
Welche Modelle?
Typisch für VPS: Llama 3 8B, Mistral 7B, DeepSeek-R1 7B, Qwen2.5-Coder 7B, Gemma 2 9B.
Sicherheit
- Port
11434standardmäßig nicht öffentlich exponieren. - 1Panel-Firewall für eingehende Verbindungen nutzen.
- Öffentlicher Zugriff nur mit Reverse Proxy, HTTPS und Authentifizierung.
- Ollama und 1Panel aktuell halten.
Kosten: Self-Hosted vs. Cloud-APIs
Bei geringem Volumen können APIs günstiger sein; bei dauerhafter Nutzung ist Self-Hosting oft günstiger mit fixer monatlicher VPS-Pauschale.
Typisch:
- VPS 4 vCPU / 8 GB: ca. 15–25 $/Monat
- Optional 1Panel Pro: 80 $/Jahr
Einsatzideen
- Privater Coding-Assistent
- Internes Wissens-Q&A
- n8n-KI-Automatisierung
- Self-Hosted-Chat-UI
- MCP-interne Tools
Fazit
Mit 1Panel ist Ollama auf dem VPS kein manuelles Großprojekt mehr — zentrale App-Verwaltung, Monitoring, Sicherheit und planbare Kosten.
Loslegen
- 1Panel kostenlos installieren → — ca. 2 Minuten
- OSS vs. Pro — Pro ab 80 $/Jahr
- 1Panel vs. cPanel